Difference between revisions of "Solving sparse systems"
(→Herzian contact) |
(→ILUT factorization) |
||
| Line 120: | Line 120: | ||
such a convergence graph for the diffusion equation is presented in figures below: | such a convergence graph for the diffusion equation is presented in figures below: | ||
| − | [[File:bicgstab_err.png| | + | [[File:bicgstab_err.png|400px]][[File:bicgstab_conv.png|400px]][[File:bicgstab_iter.png|400px]] |
We can see that low BiCGSTAB error estimate coincides with the range of actual small error compared to the analytical solution as well as with the range of lesser number of iterations. | We can see that low BiCGSTAB error estimate coincides with the range of actual small error compared to the analytical solution as well as with the range of lesser number of iterations. | ||
Revision as of 08:14, 15 May 2017
There are many methods available for solving sparse systems. We compare some of them here.

Mathematica has the following methods available (https://reference.wolfram.com/language/ref/LinearSolve.html#DetailsAndOptions)
- direct: banded, cholesky, multifrontal (direct sparse LU)
- iterative: Krylov
Matlab has the following methods:
- direct: https://www.mathworks.com/help/matlab/ref/mldivide.html#bt42omx_head
- iterative: https://www.mathworks.com/help/matlab/math/systems-of-linear-equations.html#brzoiix, including bicgstab, gmres
Eigen has the following methods: (https://eigen.tuxfamily.org/dox-devel/group__TopicSparseSystems.html)
- direct: sparse LU
- iterative: bicgstab, cg
Solving a simple sparse system $A x = b$ for steady space of heat equation in 1d with $n$ nodes, results in a matrix shown in Figure 1.
The following timings of solvers are given in seconds:
| $n = 10^6$ | Matlab | Mathematica | Eigen |
|---|---|---|---|
| Banded | 0.16 | 0.28 | 0.04 |
| SparseLU | / | 1.73 | 0.82 |
Incomplete LU preconditioner was used for BICGStab. Without the preconditioner BICGStab does not converge.
Parallel execution
BICGStab can be run in parallel, as explain in the general parallelism: https://eigen.tuxfamily.org/dox/TopicMultiThreading.html, and specifically
"When using sparse matrices, best performance is achied for a row-major sparse matrix format.
Moreover, in this case multi-threading can be exploited if the user code is compiled with OpenMP enabled".
Eigen uses number of threads specified my OopenMP, unless Eigen::setNbThreads(n); was called.
Minimal working example:

#include <iostream>
#include <vector>
#include "Eigen/Sparse"
#include "Eigen/IterativeLinearSolvers"
using namespace std;
using namespace Eigen;
int main(int argc, char* argv[]) {
assert(argc == 2 && "Second argument is size of the system.");
stringstream ss(argv[1]);
int n;
ss >> n;
cout << "n = " << n << endl;
// Fill the matrix
VectorXd b = VectorXd::Ones(n) / n / n;
b(0) = b(n-1) = 1;
SparseMatrix<double, RowMajor> A(n, n);
A.reserve(vector<int>(n, 3)); // 3 per row
for (int i = 0; i < n-1; ++i) {
A.insert(i, i) = -2;
A.insert(i, i+1) = 1;
A.insert(i+1, i) = 1;
}
A.coeffRef(0, 0) = 1;
A.coeffRef(0, 1) = 0;
A.coeffRef(n-1, n-2) = 0;
A.coeffRef(n-1, n-1) = 1;
// Solve the system
BiCGSTAB<SparseMatrix<double, RowMajor>, IncompleteLUT<double>> solver;
solver.setTolerance(1e-10);
solver.setMaxIterations(1000);
solver.compute(A);
VectorXd x = solver.solve(b);
cout << "#iterations: " << solver.iterations() << endl;
cout << "estimated error: " << solver.error() << endl;
cout << "sol: " << x.head(6).transpose() << endl;
return 0;
}was compiled with g++ -o parallel_solve -O3 -fopenmp solver_test_parallel.cpp.
Figure 2 was produced when the program above was run as ./parallel_solve 10000000.
ILUT factorization
This is a method to compute a general algebraic preconditioner which has the ability to control (to some degree) the memory and time complexity of the solution. It is described in a paper by
Saad, Yousef. "ILUT: A dual threshold incomplete LU factorization." Numerical linear algebra with applications 1.4 (1994): 387-402.
It has two parameters, tolerance $\tau$ and fill factor $f$. Elements in $L$ and $U$ factors that would be below relative tolerance $\tau$ (say, to 2-norm of this row) are dropped.
Then, only $f$ elements per row in $L$ and $U$ are allowed and the maximum $f$ (if they exist) are taken. The diagonal elements are always kept. This means that the number of non-zero
elements in the rows of the preconditioner can not exceed $2f+1$.
Greater parameter $f$ means slover but better $ILUT$ factorization. If $\tau$ is small, having a very large $f$ means getting a complete $LU$ factorization. Typical values are $5, 10, 20, 50$. Lower $\tau$ values mean that move small elements are kept, resulting in a more precise, but longer computation. With a large $f$, the factorization approaches the direct $LU$ factorization as $\tau \to 0$. Typical values are from 1e-2 to 1e-6.
Whether the method converges or diverges for given parameters is very sudden and should be determined for each apllication separately. An example of such a convergence graph for the diffusion equation is presented in figures below:



We can see that low BiCGSTAB error estimate coincides with the range of actual small error compared to the analytical solution as well as with the range of lesser number of iterations.
Herzian contact
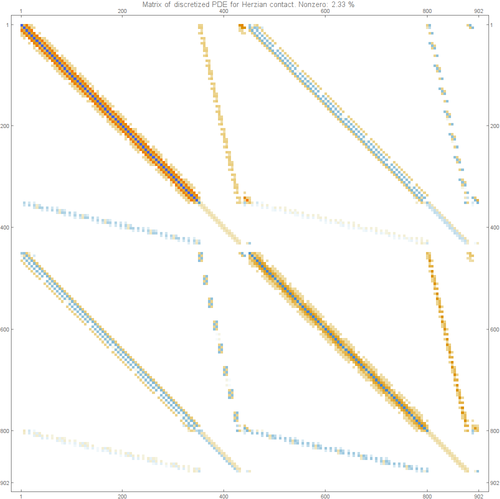
The matrix of the Hertzian contact problem is shown below:

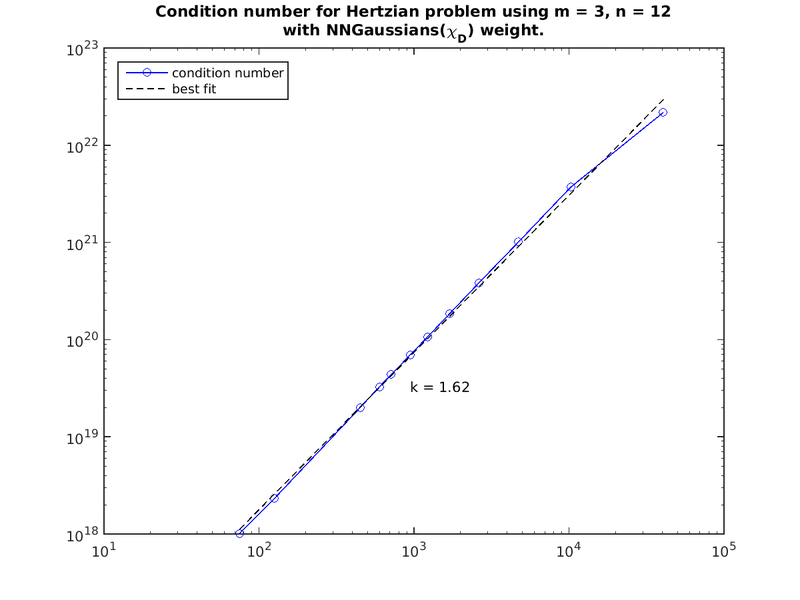
The condition number iz arther large and grows superlinearly with size in the example below.